


Why twins?
Rehearsals builds twins to recreate true taste and intangible preference, capturing a human-level precision to accurately model real-life product and decision distributions.
Induction vs. Deduction
Most approaches to predicting consumer behavior, including frontier LLMs like ChatGPT, Gemini, and Claude, use deductive reasoning. They start from general principles and theoretical averages of the “rational consumer.” But humans don't make decisions against the bucketed average. They make decisions based on the rich context of their lives. Rehearsals builds twins uniquely through inductive modeling, starting with individual cases and letting patterns emerge.
Our approach is three-fold:
1. Deep Individual Interviews:
Rehearsals runs structured conversations with interview questions backed by UX researchers and behavior economists to extract decision-making processes, values, constraints, and preferences.
2. Demographic Calibration:
Twins represent authentic market segments matching U.S. census distributions
3. Continuous Validation:
Rehearsals allows for regular testing against real-world outcome
Why should I use Rehearsals?
The era of slow human research is over. Traditional user research is extremely costly, time consuming, and lacks scale or repeatability. You spend weeks trying to plan study questions, recruiting a panel of participants, interviewing, calculating results, re-testing...again and again. Additionally, it's very difficult to pivot mid study or A/B test against a control group in a live interview.
Rehearsals Outperforms Frontier LLMs (ChatGPT, Gemini)
The Two-Step Accuracy Funnel:
Predicting consumer response to price changes requires getting two things right:
1. Screening:
Who actually qualifies to answer? (e.g., “Do you subscribe to Disney+?” or “Have you taken a flight in the last year”)
2. Distribution:
Among qualified respondents, what do they choose?
We set out to see if two frontier LLMs could succeed at predicting changes in user behavior corresponding to price changes from recent examples. Unfortunately, they fail at one or both steps. Our twins succeed at both.
| ChatGPT | Rehearsals |
|---|---|
| Figure 1 Frontier LLMs use deductive reasoning from general principles and theoretical averages of the “rational consumer”. | Figure 2 Uses inductive modeling grounded in real individual behavioral data from Rehearsals' AI twins |
Simulation Results
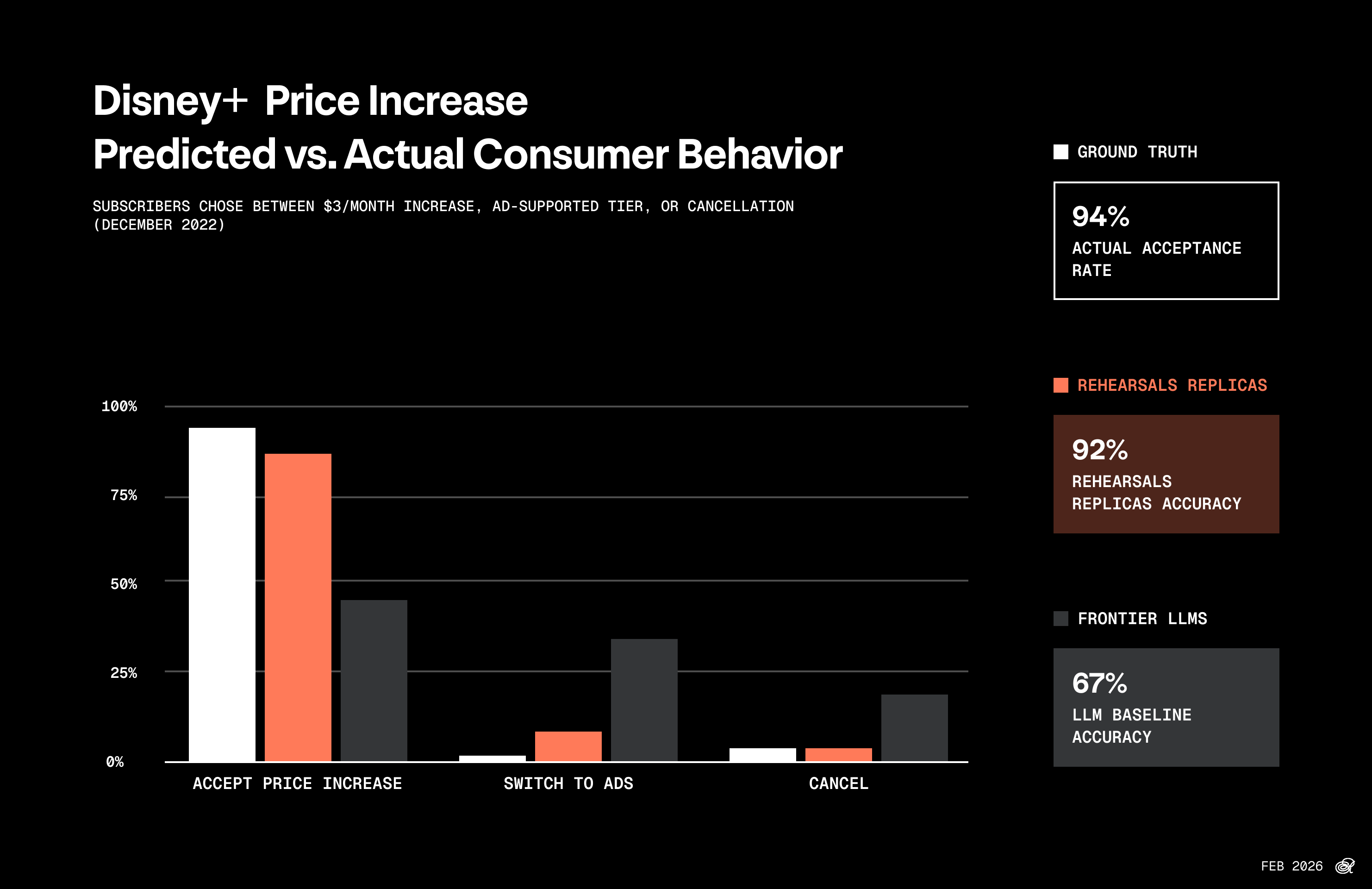
Twins correctly identified that ~19% of the population subscribes (close to the 23% ground truth) and predicted the actual distribution within 9 percentage points. Shockingly, Gemini over-qualified respondents by 15pp and badly underestimated the 94% acceptance rate, saying that only 58% would. ChatGPT nailed screening but completely missed the distribution--predicting only 38% would accept the price increase when 94% actually did. Neither baseline captured the status quo bias that dominates real subscriber behavior.
- 23% of US adults subscribe to Disney+. Among subscribers facing a $3 price increase:
- 94% accepted the increase
- 5% canceled
- <1% switched to the ad tier
| Method | Predicted Qualification | Gap from Ground Truth | Distribution Accuracy (1 - MAE) |
|---|---|---|---|
| Rehearsals twins | 18.7% | 4.3pp | 91.1% |
| Gemini 3.0 | 38% | 15.0pp | 76.0% |
| GPT-5.2 | 16% | 7.0pp | 62.7% |
Explore your business with Rehearsals
We're at a point where technology can expand the potential of what is possible. Simulation environments can run scenarios, gut-checks, and campaigns fast enough to give you human input in real-time.
Rehearsals enables you to dig deeper with your customers.
Curious to see what Rehearsals can do for you? Explore our tool or book a demo call with us. Whether you bring your own customers or use our database of twins, get real human responses for any product feedback, marketing campaign, social media asset, or customer decision.